DGraph - Part 3: RDF N-Quads
Adding or changing data is also called a mutation in Dgraph as in GraphQL. The input format here are so-called triples in the RDF N-Quad format. Such a triple consists of 3 components, a subjec , a predicate and a object. Something is ringing? Yes, exactly, there was something like that back in school a long time ago. The terms subject, predicate and object are not chosen at random here: A triple is a statement that relates subject and object to each other,
e.g. Peter Parker —is a friend of –> Mary Jane Watson
A detailed description can be found on Wikipedia.
In the first part we already worked with triples, although little was explained about it. Building triples for a mutation in Dgraph is actually just as simple as the example above:
|
|
Here we have a node with the id 0x01. This node has a field name to which we have assigned the value Peter Parker. At node 0x02 we assigned Mary Jane Watson as a name. Then we connect the two data sets with the predicate friend_of. The . at the end signals the end of the line. If a node has more fields or other connections, you can continue line by line according to this scheme. The above The example given assumes, of course, that we know the Ids of the nodes.
Mutations in Dgraph
In part we already had the first mutation in this format:
|
|
We have created new data records. So that we can do this efficiently, Dgraph has the option to work with empty nodes. Here we can use temporary IDs to create a relationship between data records. The format here is _: description. This allows us to set several fields and to define relationships between several nodes.
Combination of Queries and Mutations
It gets really efficient in the combination of queries and mutations. In Dgraph we can define variables within a query, which we can then use in a mutation.
|
|
In this example, we first look for Peter Parker in the name field and assign the Peter variable the value of the uid of our search result. We can then use the variable Peter in the mutation to update the node. The ability to work with variables here is great because it saves you time and, above all, code.
Schema definition with RDF N-Quads
I cheated a bit above. The combination of query and mutation works, but only if you change the definition of the field name a little beforehand. We need to be able to search on the field name with a function, so we have to tell Dgraph that it is a searchable field. To do this you have to click on the Schema in the Ratel interface and now you can click Bulk Edit:
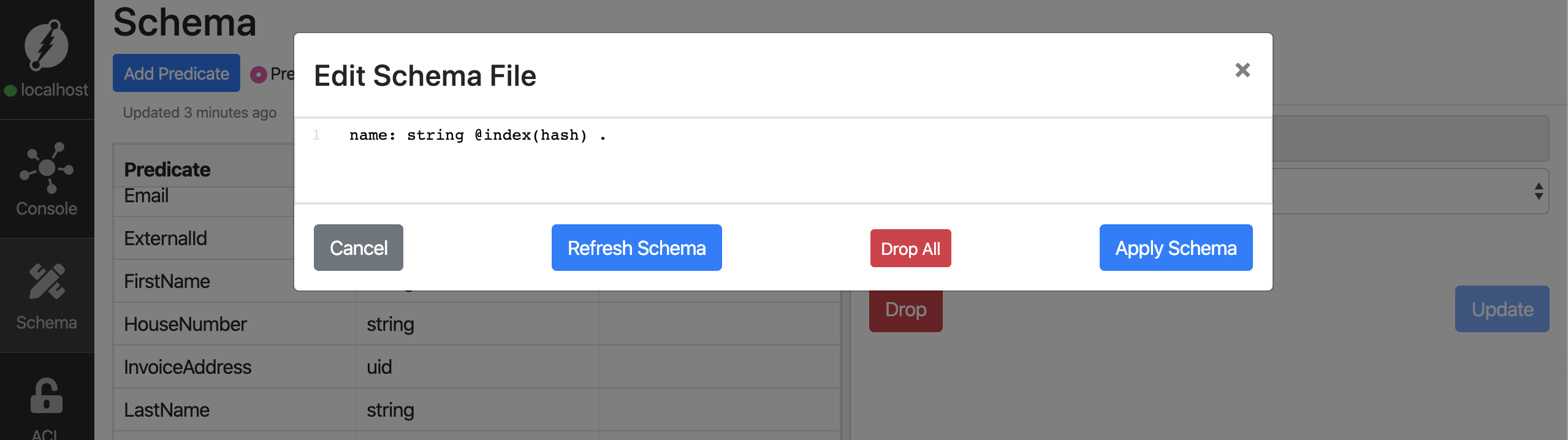
The Bulk Edit function makes sense if you want to edit several entries. However, if you only want to revise one, you can simply click on the field name:
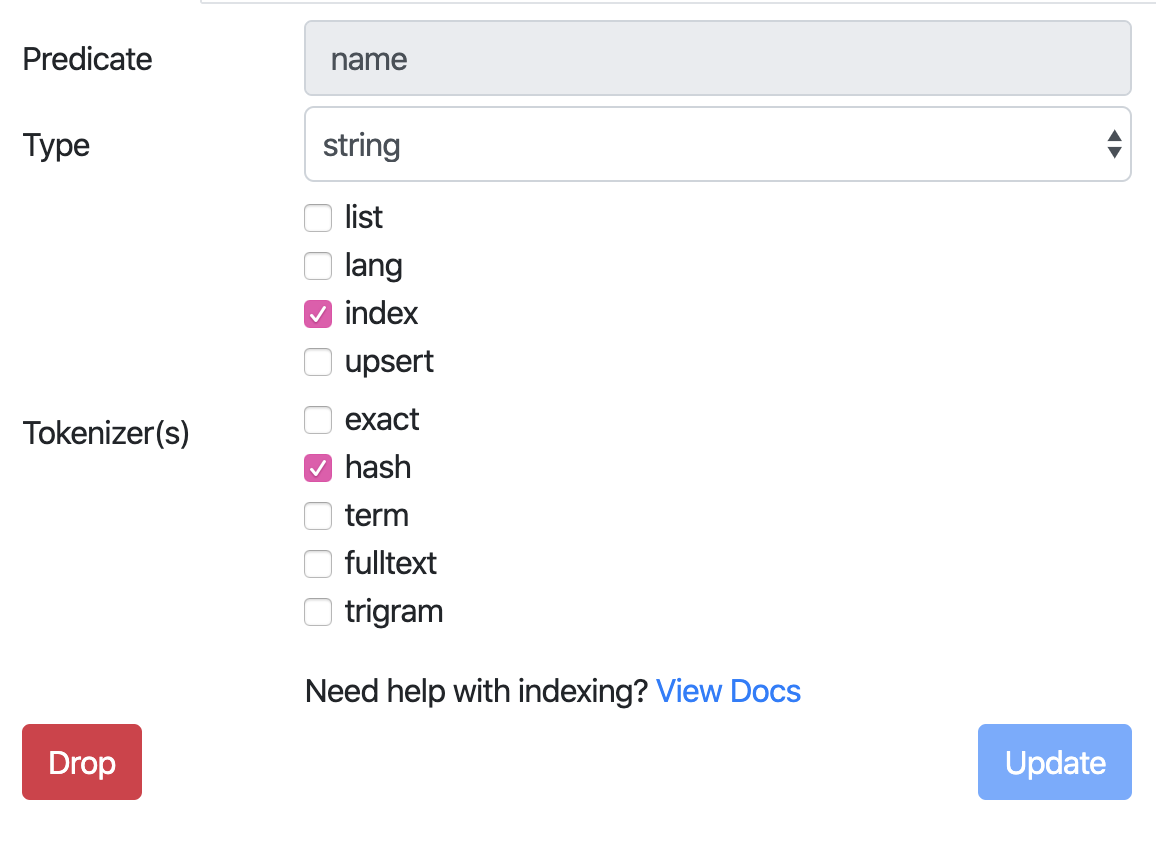
We have now made the field name searchable and now the upsert mutation works. The scheme can also be transmitted via one of the available clients. A scheme change via http e.g. with cURL is not possible for security reasons.
DGraph automatically creates a data schema based on the data you save. That means you don’t have to worry about it at first. You can see from the example above, however, that even a simple search for a specific field can no longer avoid the topic of schema. This makes a lot of sense. If every field were searchable from home, it would not be particularly performant.
Mutations in the JSON Format
Mutations can also be transmitted in JSON format, which is an enormous relief, especially for complex data sets.
|
|
It is also possible to use variables from a query for an upsert operation:
|
|
This is only a rough overview of the topic. There are further examples and information in the DGraph documentation. DGraph Documentation