DGraph - Teil 3: RDF N-Quads
Das hinzufügen oder ändern Daten wird in Dgraph so wie in GraphQL auch als Mutation bezeichnet. Das Eingabeformat sind hier sogenannte Triples im RDF N-Quad Format. So ein Triple besteht aus 3 Bausteinen, einem Subjekt, einem Prädikat und einem Objekt. Da klingelt doch was? Ja genau, so etwas gab es vor graumer Zeit einmal in der Schule. Die Begriffe Subjekt, Prädikat und Objekt sind hier nicht zufällig gewählt: Ein Triple ist eine Aussage, die Subjekt und Objekt miteinander in Beziehung setzt,
z.B. Peter Parker —befreundet mit –> Mary Jane Watson
Eine ausführliche Beschreibung dazu findet Ihr auf Wikipedia.
Im ersten Teil haben wir ja schon mit Triples gearbeitet, wenn auch wenig dazu erklärt. Der Aufbau der Triples für eine Mutation in Dgraph ist eigentlich genau so einfach wie das oben stehende Beispiel:
|
|
Hier haben wir einen Knoten mit der Id 0x01. Dieser Knoten hat ein Feld name, dem wir den Wert Peter Parker zugewiesen haben. Beim Knoten 0x02 haben wir Mary Jane Watson als Namen zugewiesen. Anschließend verbinden wir die beiden Datansätze mit dem Prädikat friend_of. Der . am Ende signalisiert das Ende der Zeile. Hat ein Knoten noch mehr Felder oder andere Verbindungen kann man nach diesem Schema Zeile für Zeile weitermachen. Das o.g. genannte Beispiel setzt natürlich voraus, dass wir die Ids der Knoten kennen.
Mutationen in Dgraph
In Teil hatten wir ja schon die erste Mutation in diesem Format:
|
|
Hierbei haben wir neue Datensätze erzeugt. Damit wir das effizient tun können hat Dgraph die Möglichkeit mit leeren Knoten zu arbeiten. Hierbei können wir temporäre Ids nutzen um einen Bezug zwischen Datensätzen herzustellen. Das Format hierbei ist _:Bezeichnung. Dadurch können wir mehere Felder setzen und auch gleich Beziehungen mehrerer Knoten untereinander definieren.
Kombination mit Queries
Richtig schick wird es in der Kombination Queries und Mutationen. Wir können in Dgraph Variablen innerhalb einer Query definieren, die wir dann in in einer Mutation nutzen können.
|
|
In diesem Beispiel suchen wir erst im Feld name nach Peter Parker und weisen der Variable Peter den Wert der uid unseres Suchergebnisses zu. Die Variable Peter können wir dann in der Mutation nutzen um den Knoten zu aktualisieren. Die Möglichkeit hier mit Variablen zu arbeiten ist einfach großartig, weil Sie Zeit und vor allem Code spart.
Schemadefinition mit RDF N-Quads
Ich habe oben ein wenig geschummelt. Die Kombination aus Query und Mutation funktioniert zwar, aber nur wenn man zuvor die Definition des Feldes name ein wenig ändert. Damit wir per Funktion das Feld name durchsuchen können müssen wir Dgraph erst noch mitteilen, dass es sich um ein suchbares Feld handelt. Dazu müsst Ihr im Ratel Interface auf den Punkt Schema klicken und könnt nun Bulk Edit klicken:
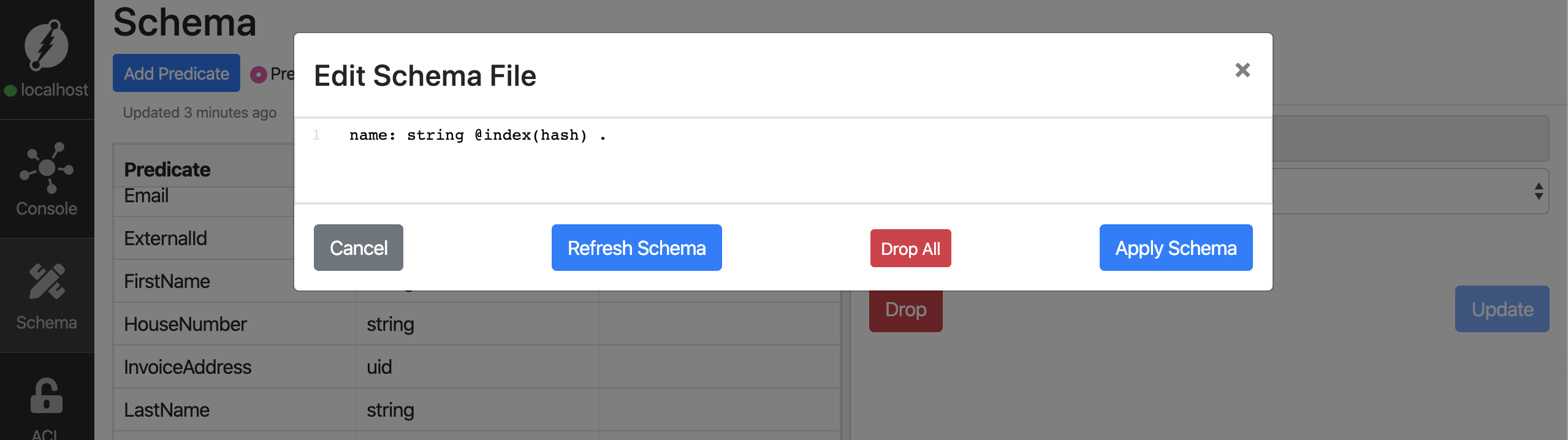
Die Bulk Edit Funktion macht dann Sinn, wenn Ihr mehrere Einträge überarbeiten wollt. Wenn Ihr jedoch nur einen überarbeiten wollt könnt Ihr auch einfach auf den Feldnamen klicken:
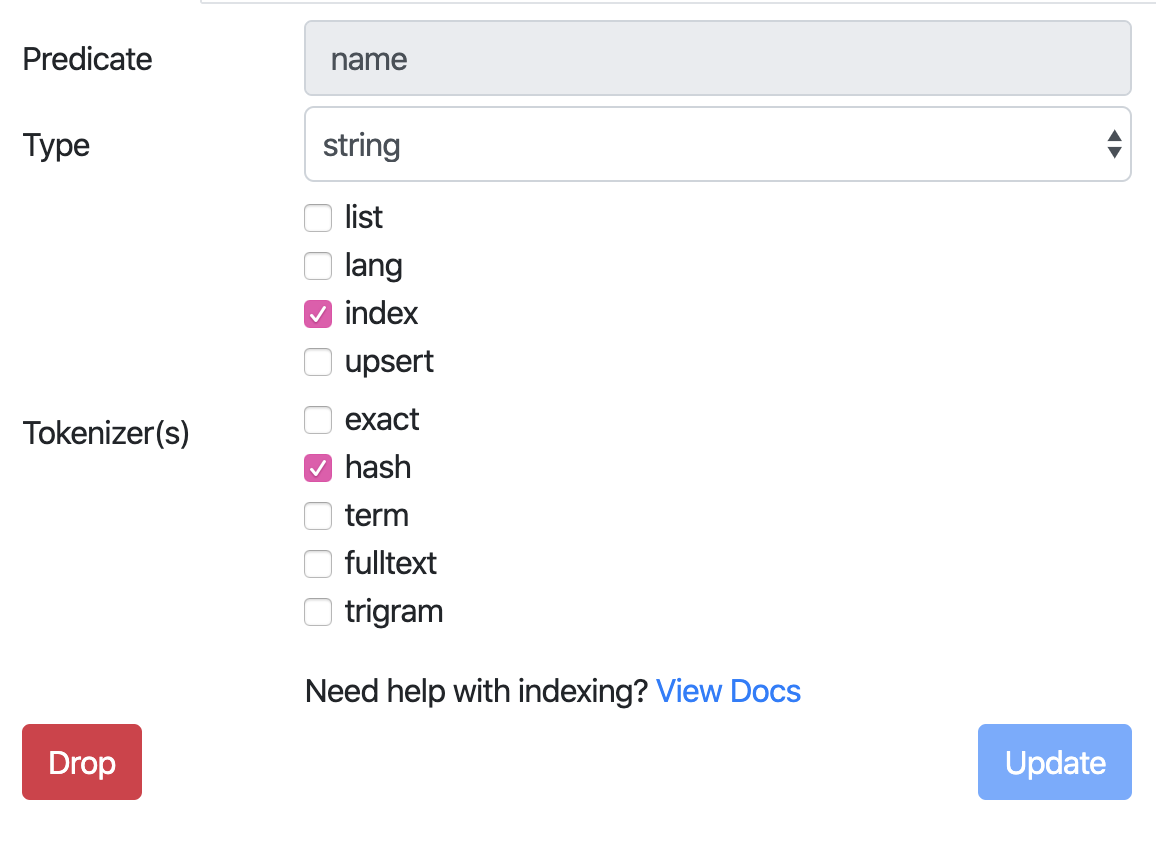
Damit haben wir das Feld name suchbar gemacht und jetzt funktioniert auch die upsert mutation. Man kann das Schema auch über einen der verfügbaren Clients übermitteln. Eine Schemaänderung über http z.B. mit cURL ist aus Sicherheitsgründen nicht möglich.
DGraph erstellt automatisch ein Datenschema anhand der Daten, die man speichert. Das bedeutet man muss sich im ersten Moment wenig Gedanken darum machen. Man sieht am oben stehenden Beispiel aber, dass man schon für eine einfache Suche nach einem bestimmten Feld nicht mehr ganz um das Thema Schema herumkommt. Das ist auch durchaus sinvoll. Wenn jedes Fel Hause aus suchbar wäre, dann wäre das nicht besonders performant.
Mutationen im JSON Format
Man kann Mutationen auch im JSON Format übermitteln was gerade bei komplexen Datensätzen eine enorme Erleichterung darstellt.
|
|
Auch die Nutzung Variablen aus einer Query für eine Upsert Operation ist möglich:
|
|
Das ist nur ein grober Überblick über das Thema, In der DGraph Dokumentation finden sich noch weitere Beispiele und Infos. DGraph Dokumentation